
 Autor: Carlos Rodrigues
Autor: Carlos Rodrigues
Data de publicação: 11/12/2025
A sustentação da operação de TI mudou radicalmente. Se a sua equipe ainda gasta a maior parte do dia “apagando incêndios” e reagindo a milhares de alertas isolados, sua operação pode estar presa em um modelo insustentável.
Por quê? Porque a fragmentação gera cegueira. Quando seus dados estão espalhados em silos, garantir SLAs, compliance e eficiência torna-se um jogo de adivinhação. Tentar monitorar isso manualmente não é apenas difícil; tornou-se humanamente impossível. A boa notícia? A tecnologia evoluiu para resolver exatamente este problema através da IA Orquestrada.
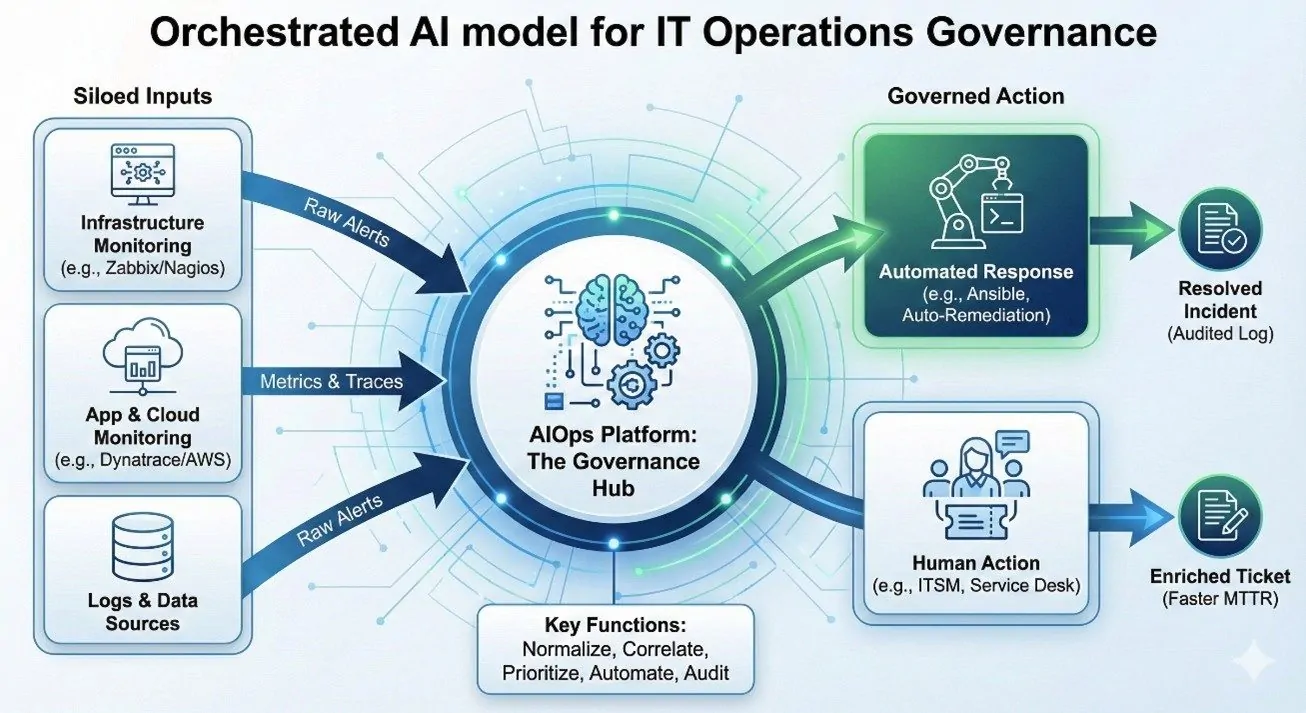
A Arquitetura da Solução: O “Hub” de Inteligência
Na prática, a IA Orquestrada funciona como um Manager of Managers (MoM). Ela não substitui suas ferramentas de base (Zabbix, Dynatrace, AWS CloudWatch, ServiceNow, etc.); ela as potencializa, integrando-se a elas para criar uma camada superior de gestão.
Mas como tirar esse conceito do papel e transformá-lo em prática na sua organização? Vamos explorar o caminho.
O Problema: A Fadiga de Alertas
Antes de falarmos da solução, precisamos reconhecer o cenário atual. Ferramentas de monitoramento geram milhares de eventos diários. A grande maioria é “ruído” — alertas de baixa prioridade ou falsos positivos que distraem a equipe dos problemas reais que afetam o negócio.
O resultado? O tempo médio para reparo (MTTR) sobe, a equipe sofre de burnout e a experiência do usuário final degrada.
O que é a IA Orquestrada na Prática?
Imagine a IA Orquestrada não como uma ferramenta passiva, mas como uma equipe de analistas digitais de elite que trabalha 24/7. Na prática operacional, ela atua em três camadas:
- Observabilidade Inteligente: Ela enxerga tudo, mas filtra o que não importa.
- Cérebro de Correlação: Ela entende que o “Erro no Banco de Dados” e a “Lentidão no Checkout” são o mesmo incidente, não dois problemas separados.
- Mãos Automatizadas: Ela executa a correção (ou o workaround) antes mesmo de um humano abrir um ticket.
Transformando Contexto em Ação: 4 Passos para Implementar
Para elevar a maturidade da sua TI e colher os benefícios da IA orquestrada (SLA melhor, eficiência e estabilidade), você precisa seguir um roteiro prático:
- Unifique a Ingestão de Dados (A Verdade Única)
A IA não pode orquestrar o que ela não vê.
- Ação Prática: Integre suas ferramentas de monitoramento (APM, Infra, Logs, Redes) em uma plataforma centralizada de AIOps (Artificial Intelligence for IT Operations). O objetivo é acabar com os silos de dados.
- Treine a Correlação de Eventos
Em vez de receber 50 alertas quando um servidor cai, a IA deve agrupar esses eventos em um único incidente com causa raiz provável.
- Ação Prática: Configure a ferramenta para entender topologia e dependências. Ensine a IA que “se o Switch A falhar, os Servidores B e C ficarão incomunicáveis”. Isso reduz o ruído em até 90%.
- Automatize a Resposta (Comece Pequeno)
A grande promessa é a redução do MTTR (Mean Time to Repair). Isso acontece via Auto-Remediation.
- Ação Prática: Não tente automatizar tudo de uma vez. Comece com tarefas repetitivas e de baixo risco, como limpeza de disco, reinicialização de serviços travados ou alocação dinâmica de memória. Conforme a confiança aumenta, expanda para fluxos complexos.
- Priorize pelo Impacto no Negócio
Este é o diferencial da maturidade operacional. Um servidor parado de teste não tem a mesma urgência que o sistema de faturamento.
- Ação Prática: Mapeie os serviços críticos de negócio na sua ferramenta de orquestração. A IA deve ser capaz de dizer: “Atenção: Falha crítica impactando 20% das vendas atuais” ao invés de apenas “CPU alta no servidor 04”.
Os Resultados Reais
Ao implementar a IA orquestrada seguindo esses passos, a mudança é tangível:
- Proatividade: Detecção de falhas antes que o usuário reclame.
- Eficiência: A equipe humana foca em inovação e problemas complexos, não em triagem de logs.
- Aprendizado Contínuo: O sistema aprende com cada incidente, tornando-se mais inteligente para a próxima ocorrência.
O Fluxo da Governança Automatizada: Do Caos à Resolução
Abaixo, ilustramos como a plataforma de IA Orquestrada atua como o cérebro central, conectando ferramentas que antes não se falavam.
| Etapa | O que acontece? | O Ganho de Governança |
| 1. Ingestão (O Hub) | A plataforma recebe dados de todas as ferramentas (Rede, App, Banco) via API. | Fim dos “pontos cegos”. Tudo o que acontece no ambiente é auditado em um único lugar. |
| 2. Correlação (O Cérebro) | A IA analisa a topologia e percebe que 50 alertas vieram de uma única falha em um switch central. | Transformação de ruído em informação estratégica. Evita pânico desnecessário. |
| 3. Decisão (O Juiz) | Baseado em regras de negócio pré-definidas, o sistema decide: “É crítico? Automatizo ou chamo um humano?” | Garantia de que o SLA e a política da empresa estão sendo seguidos rigorosamente. |
| 4. Ação (O Executor) | Se for automatizável, o script roda. Se for complexo, um ticket é aberto no ITSM já com o diagnóstico pronto. | Padronização da resposta. O erro humano é eliminado da triagem e da execução básica. |
A Prova Real: 3 Cenários do Dia a Dia (Antes vs. Depois)
Para tangibilizar o impacto dessas ferramentas integradas, vamos comparar três situações clássicas de qualquer TI e como a governança muda o jogo.
Cenário 1: O Clássico “Disco Cheio” (Automação de Rotina)
Um servidor de logs crítico atinge 95% de ocupação. Se chegar a 100%, a aplicação para.
- ❌ No Modelo Tradicional (Silos):
- O Zabbix gera um alerta às 03:00 da manhã.
- O operador N1 acorda, valida o alerta e abre um ticket.
- O analista de infraestrutura acessa o servidor via SSH, verifica quais arquivos podem ser apagados e executa a limpeza manual.
- Tempo total: 45 minutos (com risco de erro humano ao apagar o arquivo errado).
- ✅ Com IA Orquestrada (Governança Automatizada):
-
- O monitoramento detecta a tendência de alta.
- A Plataforma de AIOps recebe o evento e identifica: “É um servidor não-produtivo, política de limpeza padrão aprovada”.
- A plataforma aciona o Ansible, que executa um playbook validado de limpeza e rotação de logs.
- O ticket é aberto e fechado automaticamente no ServiceNow apenas para registro de auditoria.
- Tempo total: 30 segundos. Zero intervenção humana.
Cenário 2: A “Lentidão Intermitente” (Correlação Inteligente)
Usuários reclamam que o e-commerce está lento, mas “todos os painéis estão verdes”.
- ❌ No Modelo Tradicional (Silos):
- Cria-se uma War Room.
- Equipe de Banco diz: “O banco está ok”. Equipe de Rede diz: “O link está ok”. Equipe de App diz: “O código não mudou”.
- Horas são gastas caçando logs em ferramentas separadas até descobrir que um backup agendado estava consumindo I/O do storage.
- Impacto: Horas de indisponibilidade e frustração entre equipes.
- ✅ Com IA Orquestrada (Visão Unificada):
-
- A IA ingere dados do APM (App), métricas do Storage e Logs do Sistema.
- O motor de correlação cruza os horários: “A latência da aplicação subiu exatos 2 segundos após o início do Job de Backup no Storage X”.
- O sistema apresenta a Causa Raiz Provável no dashboard unificado.
- Impacto: Diagnóstico em minutos. A equipe atua direto na causa (parar o backup ou ajustar a janela), sem reuniões de culpa.
Cenário 3: A Queda de Link Crítico (Supressão de Ruído)
Um switch central de um Data Center perde comunicação.
- ❌ No Modelo Tradicional (Silos):
- As ferramentas de monitoramento perdem contato com os 50 servidores e 200 aplicações que estão “atrás” desse switch.
- O painel da operação fica vermelho com 250 alertas simultâneos.
- A equipe entra em pânico tentando checar servidor por servidor, sem saber por onde começar.
- Resultado: Caos operacional e dificuldade de priorizar.
- ✅ Com IA Orquestrada (Topologia):
-
- A plataforma conhece a topologia (o mapa de dependências).
- Ela entende: “Se o Switch Pai caiu, é óbvio que os Filhos (servidores) estão incomunicáveis”.
- A IA suprime os 250 alertas dos servidores e gera apenas 1 Incidente Crítico: “Falha no Switch Central”.
- Resultado: Clareza imediata. A equipe de redes é acionada direto para o hardware, enquanto o resto da operação é informado da causa raiz.
Perceba que, em todos os casos, o ganho não foi apenas “velocidade”. Foi Governança.
- No Cenário 1, garantimos que o script padrão fosse executado (compliance).
- No Cenário 2, eliminamos a cegueira dos silos de dados.
- No Cenário 3, mantivemos a organização da operação em momento de crise.
É isso que significa transformar contexto em prática.
Conclusão
A IA Orquestrada não é ficção científica; é o novo padrão para operações de TI de alta performance. Ela transforma a sustentação de um centro de custos reativo em um parceiro estratégico, estável e veloz.
Está pronto para sair do modo reativo e orquestrar o futuro da sua operação? Fale com a OnSet!
Revisão e Publicação: Alidiane Xavier



